given at the joint Harvard/MIT Technological Strategies for Protecting Intellectual Property in the Networked Multimedia Environment conference, April 1993.
The needs of university presses for intellectual property protection are a good microcosm for understanding the needs of electronic publishers in general. Systems will need to be reasonably secure (rather than utterly secure), and be flexible enough to accommodate a wide range of content forms and transaction forms. Header-based security holds promise.
INTRODUCTION
I've heard speakers at various conferences say that publishers won't be necessary in the New Online World. I think that's wrong. Publishers will survive because people want authentication and validation, both as authors and as readers. In a networked environment, the greater the volume of information, the greater the need for distillation and dependability, which publishers will provide.
University presses will survive because scholarship, academic prestige, and tenure committees will survive. An electronic publication by a university press will simply be more believable, trustworthy, and potentially important than an ftp-able file on WUarchive will be, or an electronic publication by Acme Publishing--not to mention more useful, attractive, and readable. Publication in high-quality form by a full-fledged publisher will be preferred by authors, and readers will prefer trustworthy documents as their mainstay of information. New forms of publishing will inevitably unfold, but the institution of publishing will not die out.
For the people gathered at this conference, considering methodologies for intellectual property protection, it's useful to understand the underpinnings of the sale of scholarly and academic information. Nonprofit publishers such as university presses are a particularly appropriate model, since profiteering is not one of our goals. The goal is rather to provide information of high value to the few people who'll value it highly, but who will not pay too high a price.
Network publishing will not make information too cheap to meter. In fact, the printing costs of a book--the only variable that changes in the networked environment--are generally only 15% to 20% of the overall costs of publishing. Manuscript development, peer review, copyediting, production costs like design, typesetting (read code-enrichment) and proofreading must all be considered when assessing the costs of publishing, whether that's electronic or print publishing. There are also such non-luxuries as publicity, marketing, order-fulfillment, record-keeping, and accounting which must be paid for. The value added by publishers take humanpower and brainpower, which must be financially supported. Straight-from-the-author document transmission may be cheap, but publishing isn't. The security systems we're talking about today are essential for the continuation of peer-reviewed, well-edited, well-promoted, well-designed and well-produced documents; that's why I'm so pleased to be invited to be here today.
Intellectual property concerns are at the heart of much informed hesitation to commit to electronic publishing. Protection of published information is essential, and without reasonably secure environments or systems, much of the best scholarship available will be very slow to go online.
I use the phrase "reasonably secure" intentionally. Generally, like anything under lock and key, the more secure it is, the more hassle it is to get to. Publishers aren't interested in having those serial-port dongles attached to every electronic book. Nor are we willing to force users through arduous or costly verification procedures.
Intellectual-property protection approaches must be flexible enough to vary according to the needs of the publisher (whether that's a university press, a scholarly society, an individual scholar, or a commercial publisher), and must be adaptable to the needs of the user, and to the technical capacity of the user's system.
It's clear that no single protection scheme will cover all security needs. Different kinds of documents will require different levels of protection, different forms and levels of access, as well as different subscription and pricing and distribution channels (which affect the protection demands). Therefore, before outlining specific strategies, I'd like to briefly overview some of the varied contents, and the varied protection demands called for by that content.
CONTENT HETEROGENEITY
Humanities texts, for example, are likely not to need the same degree of "timeliness" as the sciences, with which most of you, I think, are more likely to be familiar. Archival material is important: original sources. The scholar browses and mulls and finds references and makes notes. Makes marginalia for later thought. Highlights key passages. They (we) tend to want to have the entire document, in context, and easily available. The humanities scholar has a different "information-need model," if you will, than one in the sciences. In the Internet environment, humanities scholarship will require repeated and dependable access to the same documents, as well as easy interconnections to other similar documents during research.
The information content of the sciences differs quite significantly from the standard humanities content. Current information is often much more important than archival information. Frequently, texts are read once, and only rarely re-referenced. The documents themselves are visually and operationally different: there tends to be much more reference material--tables, graphs, mathematical models, graphic representations. It lends itself more to multimedia work, and will need those sorts of tools--interactive graphs, interactive models, interactive algorithms. These last interactive content models may need a different protection system--and permission system--than the text within which it lies.
Journals have a different set of needs than individual texts; they're a more direct-to-customer form of publishing than book sales, which is why journal managers are often the most interested in Internet publishing. Timeliness is often tremendously important, for which the Internet is a boon. A single security check for a selected sequence of individual articles is required.
Monographs have been declared dead, but I doubt that. I think there's room for the monograph even in an e-mail soundbite world, because it allows for context to be built brick by brick like the walls of a house. Monographs may be more likely to be downloaded and printed out than reference works, journal articles, or scientific texts. Local site ownership is more likely than online access.
Different disciplines and different forms have different information-access models, which in turn will demand different security models--most of which I can't predict. I can say that while university presses predominantly publish text-based information now, that will change to include sound and video as they become applicable.
ECONOMIC STRUCTURES
The content of the texts published will make demands upon any security structure, and must be integrated into the other great demand: working within the varied economic structures of publishing. These will change dramatically. Current theories imply that because delivery will be simpler, the business will be simpler. I think that's a misinterpretation of the complexity of the business of publishing.
Our main objective--beyond the prime objective of economic survival--is to get it into the hands of interested people.
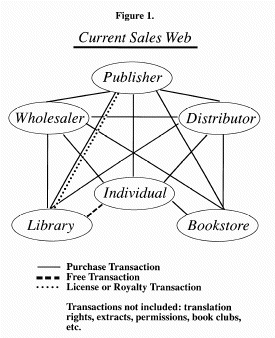
Currently, to do that we have an intricate and interconnected web of distributors, resellers, bookstores, and individuals we serve (see Fig. 1). Bookstores often buy our books from distributors and from wholesalers and from us directly. Individuals may call our 800 number to order, or may call up their bookstore, or a wholesaler, or a distributor. Libraries may order from us or from the library wholesaler or from both. Publishers sell units, which are then resold as units.
It's easiest and cheapest for us to sell units in bulk, of course, because there's less humanpower involved. We like to sell to wholesalers, and bookstores, and libraries.
But this business has been developed based on units--a commodity. Electronic publications are not units in the same way. When we shift to a network publishing framework, suddenly a welter of new connections, new possibilities, and new "networks" appear (see Fig. 2).
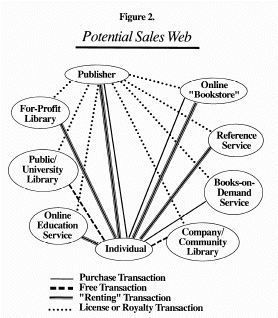
We may sell a site-license to a library exclusively for the campus-wide network. We may license to a "virtual bookstore," which functions as a sort of "for-profit library." We may license to a new kind of entrepreneur, who builds a sort of tailored educational experience and rents it over the web, and for whom our book is one license and royalty among many he must calculate. We may license to a university the rights to sell/distribute/display a specific text for a course, but only for the duration of a course, for which the students all pay a small fee, of which the publisher and author receive some proportion. We may sell directly to the customer, providing client-server systems for online access directly, or "rent" access for referencing, or sell a text for local ownership--even for printing out locally. We may use the Internet to connect up with books-on-demand printers using Docutech or Lionheart systems--high-speed PostScript printers/binders for generating reprint-like documents.
Licensing becomes dramatically important, because the same electronic text can and will be used in a variety of forms, sold by a variety of vendors, and manipulated by a variety of users, each of which will have a different security model, usage model, and pricing model.
In the networked world, we must design systems--or appropriate existing systems--that will allow us to rent, sell, and license texts, to allow these very different audiences with very different needs to view, search, annotate, copy in limited fashion, and/or virtually "own" these texts. We also must be ready to provide mixed models on demand.
Scholars who "own" an annotated online text--say a server-based display-only collection of documents--will also want to make temporary connections to other publications--to check references, make glancing checks of related documents, etc. Currently, Scholar Smith owns one collection of books outright, books she purchased personally. She also has related books she's borrowed from the library. And she "rents" information via fair-use photocopying or interlibrary loan. In the near future, we must build electronic models that allow these interconnections, even foster them, thus providing scholars with what they want: to have validated, paid-for ownership, be able to "rent" certain brief connections to other titles or journal articles, and be able to borrow access from the library, which has purchased the title or journal from a publisher.
Through all of this we must be able to make these sales (at differential costs), track these licenses and sales, confirm their use and their limits, collect payments, and pay royalties to our authors accordingly, as well as provide readers with some form of authenticity check. All without having the text easily copied by Scholar Smith to all her friends as a courtesy.
This is a tall order, and is why many models won't be put into practice right away. But it also needn't be done all at once, which is a relief. This web I describe is perhaps five years off, I'd say--or longer (if ever), if security systems aren't devised.
Let me come back to "reasonable" security, and what university presses need to make the previously described flexible desktop library possible.
REASONABLE SECURITY
From what I've seen, I don't believe there's any way to effectively build absolute data security into any ftp-able or e-mailable file, without a prohibitively significant hassle factor. Hashing and public-key encryption could work for individual texts, but unless there's a universal yet specifically-designed front-end that handles the decryption on-the-fly--and which itself cannot be copied--then either a morass of document-specific codes would result, making a hard-disk-stored "bookshelf" clumsy, or we'd end up with an array of unique and mutually exclusive front-ends cluttering up one's virtual desktop.
The viable models--in my opinion--are all variants of a client server, in which access is constrained and controlled by the server itself. This assumes a stable and direct network connection and appropriate display hardware and software, of course. The servers might belong to a library (to whom a site license is sold by a publisher), or a university, or a "virtual" bookstore, or the entrepreneur, or the on-demand printer, or the reference service, or the publisher itself.
Reasonable security is all we require. Client-server systems can and will be cracked; consequently publishers (and other server owners) will need security structures that provide the authentication systems described by Dr. Graham, to be sure that the texts which are served are the authoritative version. This can be done, I suspect, relatively easily, via a separate archive which is copied back to the server periodically to assure that the "authoritative" version is always available.
Occasional crackers who are simply borrowing or stealing access aren't so much the worry, any more than occasional shoplifters are a worry. I'm not even tremendously worried about commercial theft--to sell a text, its existence must be publicized; a thief doesn't publicize a theft. Black market bookstores simply aren't likely. I'm a bit concerned about international theft--out where copyright conventions aren't followed--but that's a matter more of trade policy and international law.
Publishers are primarily, and justifiably, concerned about local abuse. If Scholar Smith purchases access to a title, either as an "owner" or a "renter"--then we want to be sure that she doesn't have easy means to copy or print files without either notification to the publisher, payment of some secondary cost, or official permission. If Scholar Smith can copy and e-mail (or print and OCR) any title, article, or chapter, and give it to any other colleague who can then continue the copying, publishers will be reticent to make it available. What we want is reasonable security that precludes casual gross copying by well-meaning colleagues, and precludes "broadcasting" of a text by any individual. We don't want to be the Big Brother information police, but we do want means to protect our intellectual property rights.
The Z39.50 communication protocols have been--if I understand them correctly--transformative, allowing a multiplicity of systems to be built that were internally compliant, and thus interconnectable. Gopher, WAIS, Panda, World Wide Web, and other publication access systems are internally compliant, and so can work apparently seamlessly together. I'm hoping this workshop begins the process of creating a similarly flexible set of security protocols. I want a scholar to be able to have access to a multiplicity of titles from a multiplicity of publishers from a multiplicity of sources, and be able, relatively seamlessly, to have a virtual desktop which allows easy connectivity to the titles he or she "owns" or "rents" or borrows.
HEADERS AND SECURITY
Header-based security--in natural conjunction with client-server security--looks the most promising for establishing the appropriately flexible security protocols. The following list of header information is a reasonable minimum for allowing a reasonable amount of protection within many client-server models, assuming that the headers themselves were reasonably secure.
Copyright-holder information/Bibliographic information. It seems reasonable to have some variant of the standard "books in print" data included with a published document.
Publisher's electronic address, to be used for a variety of purposes--communicating transactions, checking authenticity, perhaps verifying ownership via a message transaction sent to that address.
Authentication-site. This is the address from which a hash-number or other unique identifier--derived from the text itself--can be checked against the version onscreen. This may differ from the publisher's own address. A variant on the authentication-site might be an "access-site" tag, which would allow access only if the server's IP address matched the code.
Printable/nonprintable/amount printable; Copyable/noncopyable/amount copyable. This would function as a "public-domain/non-public-domain" identifier as well, thus allowing those who didn't give a hoot about redistribution to provide a means of indicating that. This data might also allow some control over redistribution, while still allowing limited fair-use copying.
License information: n/a for individual sales, but otherwise would include a) number of concurrent viewers; b) access-site limits (as in "accept only readers with login addresses from the following nodes"; and c) identification of licensee (in case of illegitimate retransmission).
Hashed/NotHashed, encrypted/not encrypted. For some publishers and for some documents, encryption of some kind is likely, even if unwieldy.
Time stamping, which for us would be "date of publication."
Duration of copyright on the work.
Character set used by the document.
Searchable/not searchable--if we have "knowbots" hunting around, we must have some scheme that allows searching without retrieving--so that my knowbot can tell me that there's a resource that's exactly what I've been looking for, if I want to buy it.
Coding scheme (raw text, SGML-enriched, PostScript, Acrobat, TEX, etc.)
Attached-file information--are illustrations, graphs, algorithms, figures, and tables original and subsumed under the overall copyright? If they are "permission" inclusions--elements copyrighted elsewhere for which permissions have been obtained--where do their permission-headers lie? How can those elements be protected independently?
One of my problems defining the list above is that security structures seem to be unavoidably intertwined with the access system using them. A security structure that is flexible enough to provide a wide range of architectures with tools for building systems is also probably flexible enough for there to be an underground of front-ends written that circumvent the restrictions--perhaps even those restrictions that are server-based, since the front-ends will be reading and responding to the headers.
Some client-server systems could have a security system that validated access by comparing client codes, client codes plus account address, and/or server codes plus address plus password. But those security structures won't mean anything if the user can easily print out the entire file, or use the flash-OCR tools that are around the corner, or use some other tool for snaring the file as it displays on the screen. Some of that is unavoidable--what we want is that stealing be so awkward that it must be willful theft rather than a just a lapse into the ethical grey zone.
It may be that "authoritative versions" are the final "security," and that having "authoritation centers" may be necessary. A Library of Congress-like bank of hash-scheme authoritative-version proofs for public-domain documents, and similar banks held by the publishers of copyrighted information, might be useful.
I'm not able to say what system or combination of systems is best. Would that I could. But I'm hopeful that the sorts of solutions I'm hearing today, and hope to continue to hear, can be combined in a manner that allows publishers to feel secure enough on the Internet to make available the vast array of scholarship that we publish.
SUMMARY
What I hope I've done today is describe the publisher's perspective on the needs for security, and show the complexity of the interconnections between resellers, retailers, lenders, and individuals with which we deal every day. We want to provide scholars and students and the reading public with a variety of options which suit the needs of the text, the researcher's method, and the idiosyncratic needs of the reader. We want to be able to serve our customers, whoever and wherever they are. And we want to be able to feel reasonably secure that our publications aren't being copied freely everywhere around the world.
We want an environment where scholars, students, and interested readers can be sure that the information they're getting is dependably available, certain of worth, and unerringly trustworthy, and where millions of items are available relatively seamlessly. The best qualities of the present system--flexible and mixed distribution, flexible and mixed access, flexible and mixed ownership--need to be built into the security protocols that are devised.
We can't do it alone--we don't have the programming expertise. But I'm hopeful that those protocols can be devised, and I'm hopeful that university presses can help structure and test those protocols in the real, virtual world of the Internet by being partners in the creation of the protocols.
On April 2 and 3, 1993, four organizations involved in networking and multimedia issues sponsored a two-day workshop at Harvard's John F. Kennedy School of Government to address the problem. These organizations -- the Coalition for Networked Information, the Interactive Multimedia Association, the MIT Program on Digital Open High Resolution Systems, and the Information Infrastructure Project in the Kennedy School's Science, Technology and Public Policy Program -- represented a set of different perspectives on what all saw as a broad common problem.
Back to Michael Jensen's home page